The Refactoring Avalanche
Software is an intriguing discipline, and one of its most captivating aspects is how small events have humongous consequences. A recent exercise in refactoring at one of my projects showed me how seemingly tiny changes could trigger huge improvements in understanding and productivity. Some refactorings aren't dissimilar to a snowflake setting off an avalanche.
I was working on an application that processed data representing railway networks (or topologies). One core functionality was consolidating different railway representations into an all-encompassing view–think of it as having the traffic plotted on a road network map.
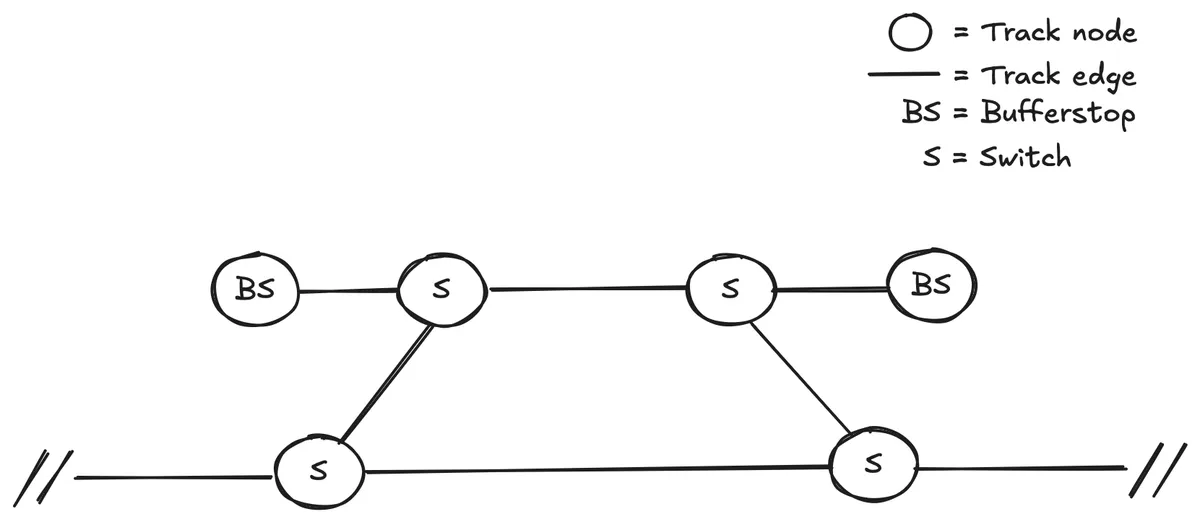
a simplified railway topology
First, I must explain a little context regarding this (simplified) topology in order to get you up to speed on the domain. Railway topologies are often represented using edges and nodes. Edges connect two nodes to each other. In this example, and the later code samples, I distinguish between two types of nodes: a switch and a buffer stop. A track switch allows trains to go from one track to the other. The buffer stop is there to prevent the train from exceeding the end of the track.

Track switch

Buffer stop
Back to the problem at hand, consolidating railway datasets. It sounds simple, but reality never is. Correlating data between different sources was not easy, so we had to create an intricate algorithm. As more cases arose, however, it became unworkable.
One of the major problems was our model of the railway network underpinning the algorithm at the time. The model was a flat structure: edges only knew their nodes by reference and not directly–almost like database normalization. It wasn't ideal, but since we'd inherited it, it took us a long time to consider alternatives.
case class RailwayData(
nodes: Set[TrackNode],
edges: Set[TrackEdge],
// other 'flat' data
)
Flat top-level structure
case class TrackNode(
id: UUID,
nodeType: NodeType,
// other properties
)
sealed trait NodeType
case object BufferStop extends NodeType
case object Switch extends NodeType
case class TrackEdge(
from: UUID,
to: UUID,
length: Double,
// other properties
)
Edges only knew nodes via their ids
To be able to evolve the consolidation algorithm, we set out to improve it. We went back to the drawing board and built it up from scratch. In the process, we made some improvements, which turned out to be unexpectedly instrumental in our later success.
For instance, one of the first things we did was to create a small extension to the existing model that made an edge know its nodes directly. We threw in some logic to easily convert between the existing model and the new one, and we were good to go. Tiny change, unprecedented payoff. We no longer had to do lookups for every node we encountered on our edges; we could just ask the edges themselves!
def isInnerEdge(edge: TrackEdge, context: RailwayData): Boolean = {
val maybeInner: Option[Boolean] = for {
from <- context.findNode(edge.from)
to <- context.findNode(edge.to)
} yield from.nodeType == Switch && to.nodeType == Switch
maybeInner.getOrElse(false)
}
Old situation: every question needed full context and lookups to answer
case class TrackEdge(
from: TrackNode,
to: TrackNode,
length: Double
// other properties
) {
lazy val isInner = from.nodeType == Switch && to.nodeType == Switch
}
New situation: TrackEdges knew TrackNodes directly, no need for lookups!
Previously, we modeled the nodes as separate properties (from and to) on an edge, requiring any check involving a node on an edge to consider each one individually. It got even worse when comparing nodes on different edges. However, the advent of directly connected nodes sparked the idea of creating a Set out of them. This change set off another landslide of new possibilities. Now, we could use the full power of the collections APIs to filter, search, compare, etc.
def areConnected(
edge1: TrackEdge,
edge2: TrackEdge,
): Boolean = {
(edge1.from == edge2.from || edge1.from == edge2.to) ||
(edge1.to == edge2.from || edge1.to == edge2.to)
}
Old situation: some questions were incredibly painful to answer
case class TrackEdge(
from: TrackNode,
to: TrackNode,
length: Double
// other properties
) {
lazy val nodes: Set[TrackNode] = Set(from, to)
def connectedTo(other: TrackEdge): Boolean =
nodes.intersect(other.nodes).nonEmpty
}
New situation: the same question was now trivial!
The two ideas combined triggered even more ideas, almost like a flywheel that kept accelerating. Now, we could add domain-centric behavior to the model, such as methods answering questions like what type of edge we were dealing with. Was it an edge connecting track switches, or was it one that ended the track?
case class TrackEdge(
from: TrackNode,
to: TrackNode,
length: Double
// other properties
) {
lazy val nodes: Set[TrackNode] = Set(from, to)
lazy val switches: Set[TrackNode] = nodes.filter(_.nodeType == Switch)
lazy val bufferStops: Set[TrackNode] = nodes.filter(_.nodeType == BufferStop)
lazy val isInner: Boolean = switches.size == 2
lazy val isOuter: Boolean = !isInner
// other methods
}
Because of the new possibilities our domain model was getting more and more useful
Another crucial breakthrough was the creation of a new building block: Topology. At first, all it did was offer a convenient place to put a subset of the data–only nodes and edges. But as the algorithm grew, more and more logic naturally ended up in this new-found abstraction. It turned out to be a major missing concept in our application, and with every method we added, we could imagine new use cases for it–new ways it could deliver value. Not only that, it allowed us to solve the same problem we had before, consolidating different perspectives on railway topologies, but we could now do it at an unprecedented pace and a higher level of abstraction.
case class Topology(
nodes: Set[TrackNode],
edges: Set[TrackEdge]
) {
def inner: Topology = Topology(
nodes.filter(_.isInner),
edges.filter(_.isInner)
)
}
Design changes allowed us to solve problems at an increasingly higher level of policy
Finally, like a chain-reaction, each of these changes sparked new ideas in turn. For instance, we're now considering implementing the topology using a Graph data structure internally, to answer network-related questions more effectively. Furthermore, we are thinking about modeling our edges as Algebraic Data Types, such as an InnerEdge which could only be constructed using two points, or an OuterEdge requiring both a point and a bufferstop. This would enforce invariants at compile time, rather than with tests, or worse, at runtime.
Summary
The best part and most curious about all this was that none of us consciously set out to improve the model, but it turned out to be critical to our success. Neither were we able to predict just how much impact the changes would have on our ability to solve the problem at hand and future problems, too.
Refactoring, and software design in general, are peculiar things. They always remind me of a game I used to play when I was young: Age of Empires. In the game, you start out knowing nothing of the territory around you–it's all hidden by the so-called fog of war. Every step you take reveals only the next bit of territory upon which you must base your following actions.
The same goes for software design. Each step you take reveals the next options, but you're never quite sure what lies just around the corner. That next step might set off a chain reaction of incredible outcomes. All you need to do is put one foot in front of the other and trust the process of discovery.